데이터 분석의 가장 기본적인 단계는 테이블에 있는 데이터를 특정 컬럼 기준으로 집계 하는것이다.
* 데이터 집계를 하려면 GROUP BY 절과 집계 함수를 동시에 사용해야한다
GROUP BY절은 아래와 같이 WHERE 절과 ORDER BY 절사이 위치해
집계할 대상 컬럼이나 표현식을 명시하면 된다. ( GROUP BY절에 명시한 컬럼이나 표현식은 SELECT절에도 명시해야됨!)
|
1
2
3
4
5
|
SELECT station_name
FROM subway_statistics
WHERE gubun = '승차'
GROUP BY station_name
ORDER BY station_name
|
cs |

주요 집계함수
(집계 함수는 SELECT 절에서만 사용할수 있다.)
| COUNT (expr) | expr의 전체 개수를 반환 . 보통 *를 사용하는데 SELECT 문에서 조회된 전체 데이터 건수를 알수 있음 |
| MAX (expr) | expr의 최대값 반환 |
| MIN (expr) | expr의 최소값 반환 |
| SUM (expr) | expr의 합계 반환 |
| AVG (expr) | expr의 평균값 반환 |
| VARIANCE (expr) | expr의 분산 반환 |
| STDDEV (expr) | expr의 표준편차 반환 |
사용 예) passenger_number는 승객수컬럼이고, 함수로 비교해 가상의 컬럼으로 결과값을 출력해준다
집계함수나, GROUP BY절 둘다 단독으로 사용하면 의미가 없고 둘을 결합해 사용해야한다
|
1
2
3
4
5
6
|
SELECT COUNT(*) cnt
,MIN(passenger_number) min_value
,MAX(passenger_number) max_value
,SUM(passenger_number) sum_value
,AVG(passenger_number) avg_value
FROM subway_statistics;
|
cs |

위에 GROUP BY 절과 집계 함수를 같이쓴다면 아래와 같은 형태가된다
|
1
2
3
4
5
6
7
8
9
10
|
SELECT station_name
,boarding_time
,gubun
,MIN(passenger_number) min_value
,MAX(passenger_number) max_value
,SUM(passenger_number) sum_value
FROM subway_statistics
WHERE station_name IN ('구로디지털단지(232)')
GROUP BY station_name, boarding_time, gubun
ORDER BY station_name, boarding_time, gubun
|
cs |
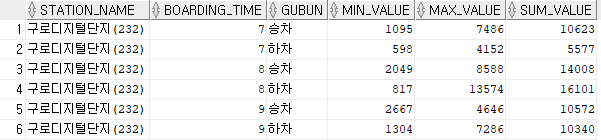
위와 같은 데이터들을 상세하게 조회하려면 WHERE 절을 생각할텐데, 집계 함수는 SELECT 절에서만 사용할수 있다.
이럴때 사용하는게 HAVING절이다.
HAVING절 (WHERE 절의 기능과 비슷하지만 GROUP BY절과 함께 사용되어 집계 쿼리의 조건절 역할을 한다)
GROUP BY 절과 함께 사용되며 집계 함수 결과값 조건으로 걸때 사용한다.
|
1
2
3
4
5
6
7
8
9
10
|
SELECT station_name
,boarding_time
,gubun
,MIN(passenger_number) min_value
,MAX(passenger_number) max_value
,SUM(passenger_number) sum_value
FROM subway_statistics
GROUP BY station_name, boarding_time, gubun
HAVING SUM(passenger_number) BETWEEN 15000 AND 16000
ORDER BY sum_value DESC
|
cs |

번외로, DISTINCT 키워드를 사용하면, SELECT 절에 'DISTINCT 컬럼명' 형태로 사용하면
해당 컬럼에 들어 있는 값에서 중복 값을 제외한 유일한 값들만 조회되서 GROUP BY절을 사용한 효과가 난다.
'데이터베이스' 카테고리의 다른 글
| [Oracle] 테이블간 관계 맺기 - 조인 (1) | 2021.02.13 |
|---|---|
| [Oracle] 집합쿼리 ( UNION ALL, UNION, INTERSECT, MINUS) (0) | 2021.02.11 |
| [Oracle] SQL 연산자와 주요 SQL함수 (0) | 2021.02.10 |
| [Oracle] 데이터 조회, SELECT 문 (1) | 2021.02.09 |
| [Oracle] 데이터 입력과 삭제 (0) | 2021.02.09 |